设为首页
收藏本站
注册账号
登录
|
搜索
搜索
本版
文章
帖子
用户
门户
Portal
论坛
BBS
网赚问答
科教问答
平面设计
网站制作
软件开发
网络运维
网教网
»
论坛
›
网教网
›
网络运维
›
阿里云运维全观测提效降本最佳实践
返回列表
发新帖
查看:
121
|
回复:
1
阿里云运维全观测提效降本最佳实践
[复制链接]
一生平安幸福
一生平安幸福
当前离线
积分
8
1
主题
4
帖子
8
积分
新手上路
新手上路, 积分 8, 距离下一级还需 42 积分
新手上路, 积分 8, 距离下一级还需 42 积分
积分
8
发消息
发表于 2022-11-30 13:12:02
|
显示全部楼层
|
阅读模式
导读:
本次给大家带来的分享是的运维全观测提效降本的最佳实践,整体方案是基于阿里云 Elasticsearch 进行实现,
主要围绕以下三个方面来展开:
运维全观测现状
全观测场景下常见问题和解决方案
案例 Usecase
<hr/>分享嘉宾|闫勖勉(三秋)阿里云 产品解决方案架构师
编辑整理|闵强 海致星图
出品社区|DataFun
<hr/>
01/运维全观测现状
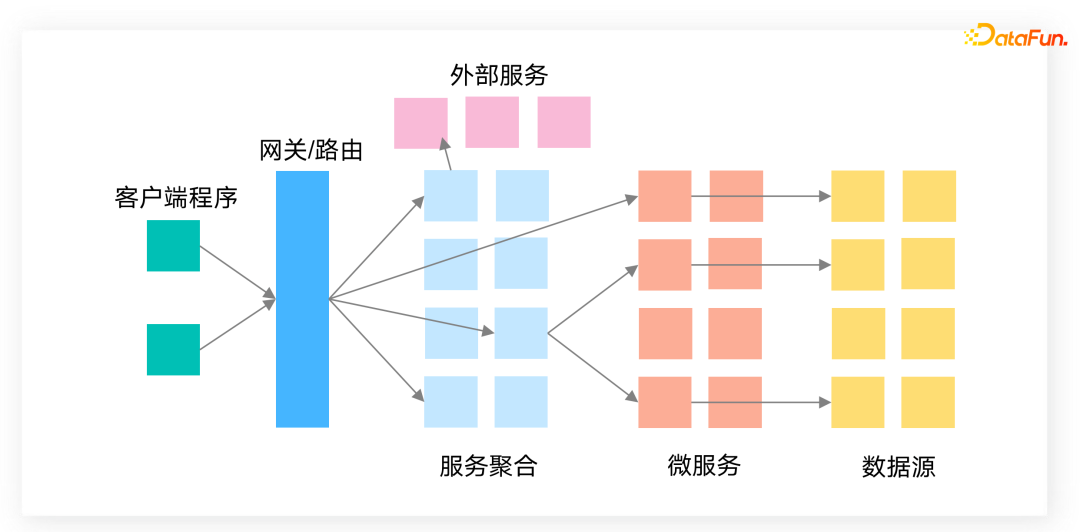
现今在运维监控方面存在越来越多的挑战,使用简单的拓扑结构并不能完全规划明晰整体网络架构。
具体来看
,一是基础设施架构复杂,整体架构包含多种服务器、GPU、网络设备、安全及存储设备等。二是服务多样、层次多级、分布化明显。分布式服务越来越多地被采用,且从用户端、网关、外部服务、服务聚合到整体数据源的数据层次、链路非常之多。三是容器化、自动化运维。由于各种服务之间的调用关系、编排错综复杂,如何去监控服务正常运行并快速排查异常,是运维全观测场景下面临的严重挑战;且随着开发和运维的结合,监测和开发的工具越来越多,自动化运维也变得更加繁杂。四是云原生架构运维。随着K8S、沙箱项目等各种云原生架构越来越多,对运维监控也是一项挑战。
整体来看,从硬件到服务上的转变,导致运维监控面临越来越多的挑战
。硬件层面从虚拟化到容器化,软件层面从单机到 N 层、SOA,再到微服务,都面临挑战逐渐升级的过程。
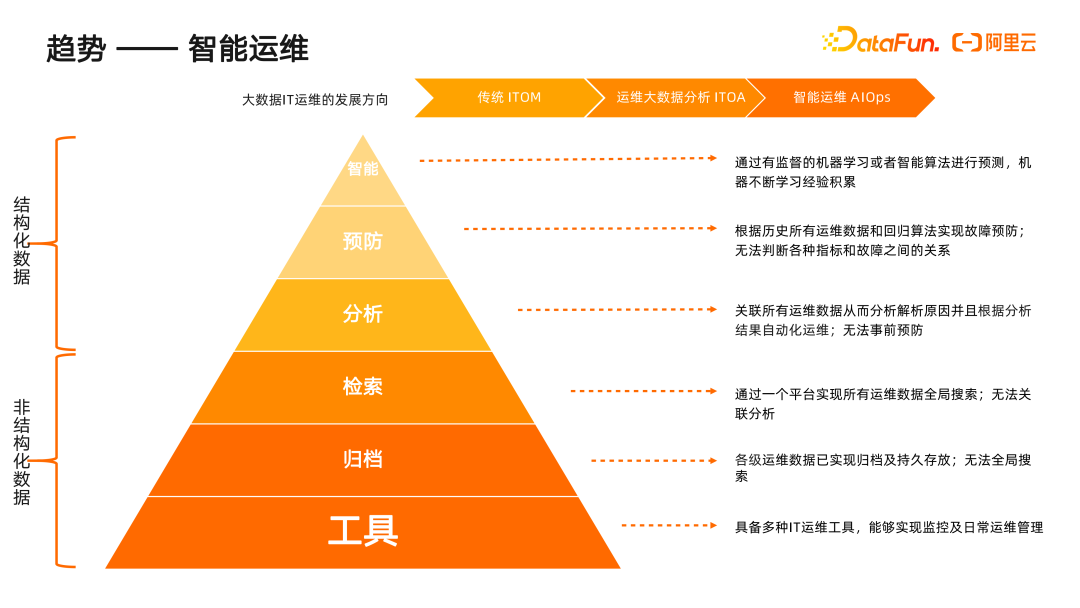
面向业务侧的需要,运维全观测的升级迭代趋势是智能运维
。在日常运维场景下,大数据IT运维的发展方向从传统 ITOM,到运维大数据分析 ITOA,进一步到智能运维 AIOps。运维系统从满足日常管理的单个IT运维工具逐渐升级,先是增加了集中存放以及持久化的能力,然后增加了全文检索的非结构化数据处理能力,其次增加了数据的整体预处理能力,并对结构化数据进行分析、建模,开展回归预测、异常点检测,根据历史运维数据实现故障预防的效果,最终达到系统级的智能运维。同时随着智能运维系统等级的提升,对数据的预处理、结构化程度等要求也越来越多,从而最终使运维系统变得更加敏捷、智能。
--
02/全观测场景下常见问题和解决方案
那么一个好的运维全观测系统需要满足的能力有哪些?我们可以做出如下提问:
首先,这个运维全观测系统的部署架构是什么,用了多少资源,性能怎么样?其次还包括它的调用关系、负荷状态、应用接口调用情况、服务接口总览、响应情况,以及调用频率、调用问题、调用瓶颈、关键路径、找谁处理等等。这一系列问题和需求都需要由一个好的运维全观测系统所满足。而满足以上这些需求,我们需要的是一个整体功能全面、鲁棒性强、被多方验证过的运维全观测系统。目前在业内被大量企业成熟验证过的 ELK 系统就是一款非常好的选择。
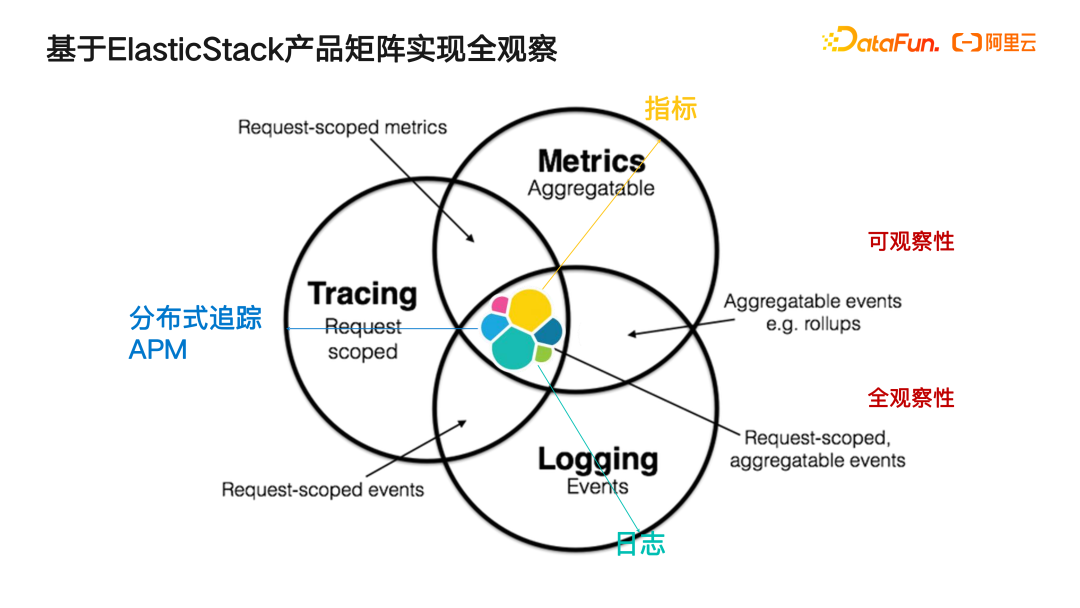
基于 ElasticStack 产品矩阵,可以从指标、日志、分布式追踪 APM 这三大场景来提供全面的支撑。同时 ELK 系统对于结构化和非结构化数据的处理保持了非常均衡的状态,我们可以在它之上进行非结构化数据的检索、结构化数据的分析,甚至进行一些端到端运营场景的简单建模训练以及推理预测。以上都可以在 ELK 这一个技术栈下实现其全部能力。
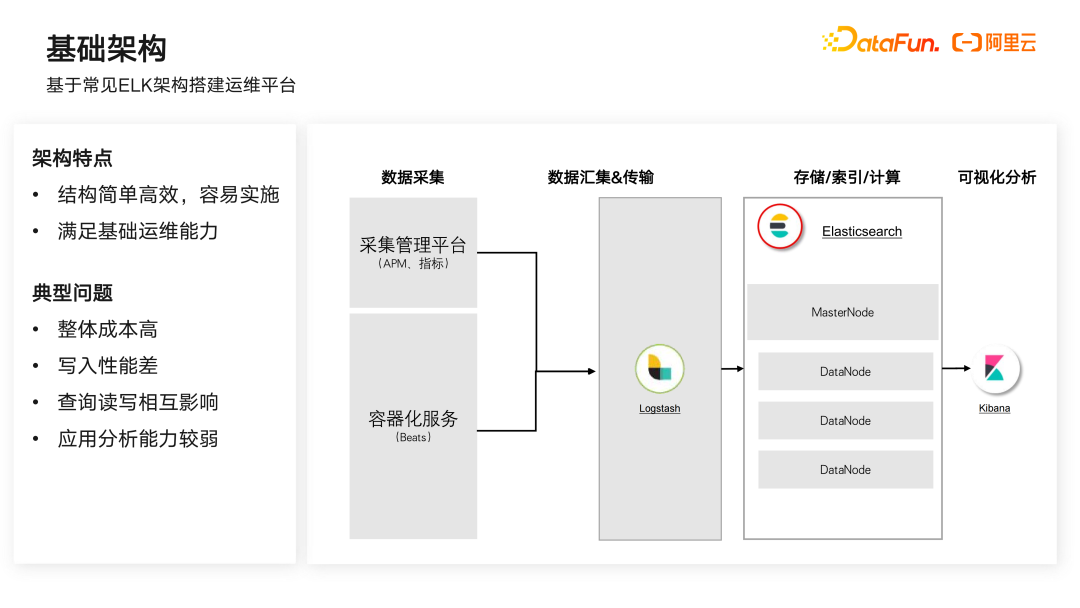
基于常见 ELK 架构搭建运维平台,其特点是结构简单高校、容易实施,能够满足基础运维能力。它一般由数据采集、数据汇聚&传输、存储/索引/计算、可视化分析构成。数据采集一般是各种采集管理平台,如 APM、指标处理的后端进行采集,还包括 Beats 等一些容器化的采集工具 Agent 来进行数据采集。数据采集之后经过 Logstash 进行传输,然后进入到 Elasticsearch 中进行数据存储、加工、检索、分析,最后在 Kibana 中进行可视化。但以上这套系统还存在一些典型问题,如整体成本过高、写入性能差、查询读写相互影响、应用分析能力较弱等。
针对以上问题我们给出了基于阿里云 Elasticsearch 解决方案,具体从以下四个维度来分析并解决。
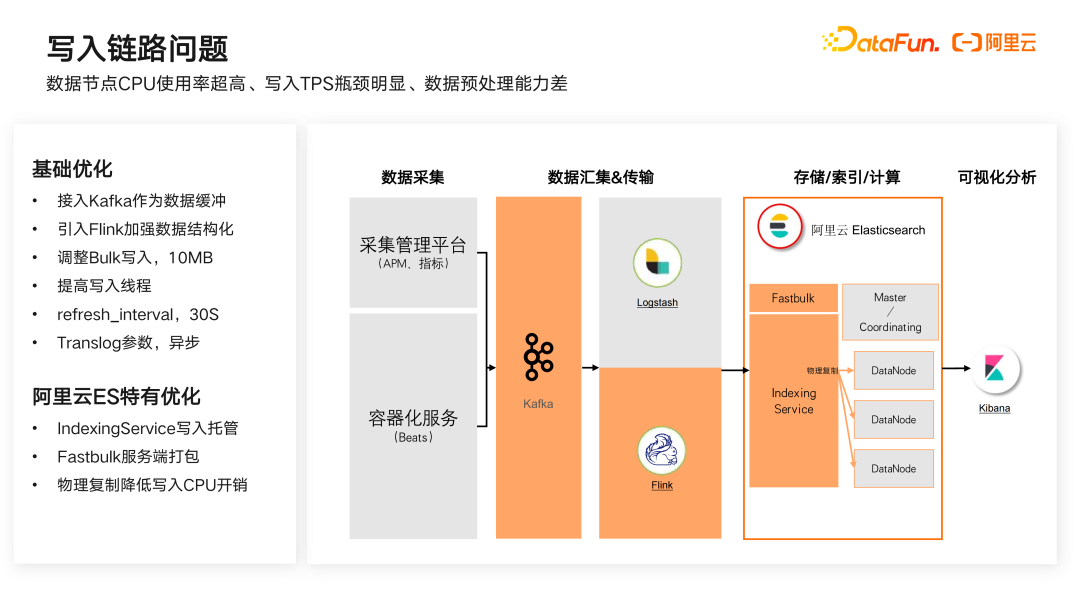
一是写入链路问题。其关键是数据节点 CPU 和内存使用率超高、写入 TPS 瓶颈明显、数据预处理能力差。
对此我们采用了两方面的优化手段
,
首先是基于 Elasticsearch 原始开源版本的基础优化
,比如引入 Kafka 作为缓冲层,将数据进行队列化,从而达到提到整体写入效率;引入 Flink 加强数据结构化处理,Kafka 加 Flink 作为经典的流式处理链路可以完成数据的机构化和预处理;还包括调整 Bulk 写入配置,通常 Elasticsearch 标准的写入效率是在 10M/Bulk 上下;还可以通过调整提高写入线程,充分利用资源;可以调整 refresh_interval 时间,在没有特殊要求的日常场景下,一般将其配置为 30 秒,从而减少 Refresh 次数,提高写入性能;最后可以修改 Translog 参数,比如调整为异步写入。
其次我们可以采用阿里云 Elasticsearch 的特有优化手段
。包括采用 IndexingService写入托管,可以在数据流写入的时候,可以在超大共享集群中完成 Indexing 的构建,使得用户可以灵活使用其中的资源,避免所有流量都占据用户的持有集群。用户的持有集群主要担负查询压力,可以大大降低资源消耗并提高持有集群的稳定性。另外采用 Fastbulk 服务端打包构成一个小的缓冲,在每次请求之后聚合成一个适合 Elasticsearch 写入的约 10M 左右的数据量,通过动态调整 Bulk 在每达到 10M 左右时进行写入,在服务端实现了 Bulk 的管理。最后还包括使用物理复制降低写入时 CPU 开销,即把 Segment 拉取到 DataNode 中,避免用户的持有集群 DataNode 进行索引构建的操作,从而可以大大降低 CPU 消耗。
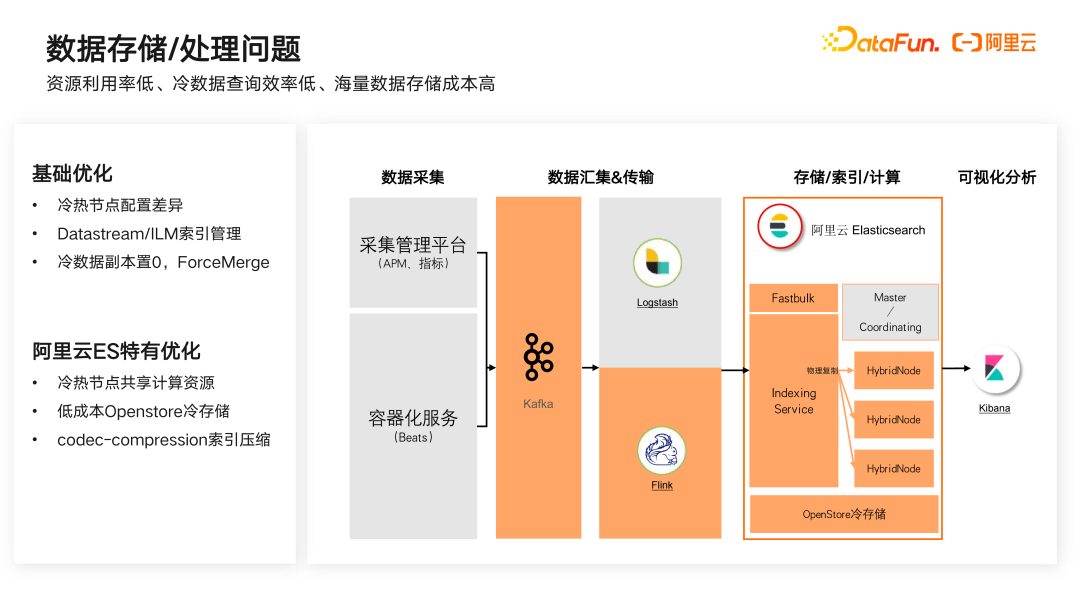
二是数据存储/处理问题。其关键是资源利用率低、冷数据查询效率低、海量数据存储成本高。
同样我们通过两方面去优化。首先是基础优化方面
,采用冷热节点配置差异,如使用SSD 来存储热数据,SATA 盘或高效云盘用来存储冷数据从而降低部分成本。通过 DataStream/ILM 索引管理来实现动态资源生命周期的调度。采用冷数据副本置零,在调整冷数据时进行 ForceMerge。
其次采用阿里云 Elasticsearch 特有优化措施,可以更好地解决用户通点
。包括冷热节点共享计算资源,将 DataNode 变成冷热节点共享的计算资源,从而使热数据采用 SSD 存储的同时,对于冷数据采用 Openstore 的机制。采用这种机制的整体成本比高效云盘降低 65% 以上,同时查询效率比高效云盘高 10% 左右。另外在数据写入的时候,还可以采用 Codec-Compression 索引压缩插件,相比 Elasticsearch 原生的压缩能力提升了 30% 左右。
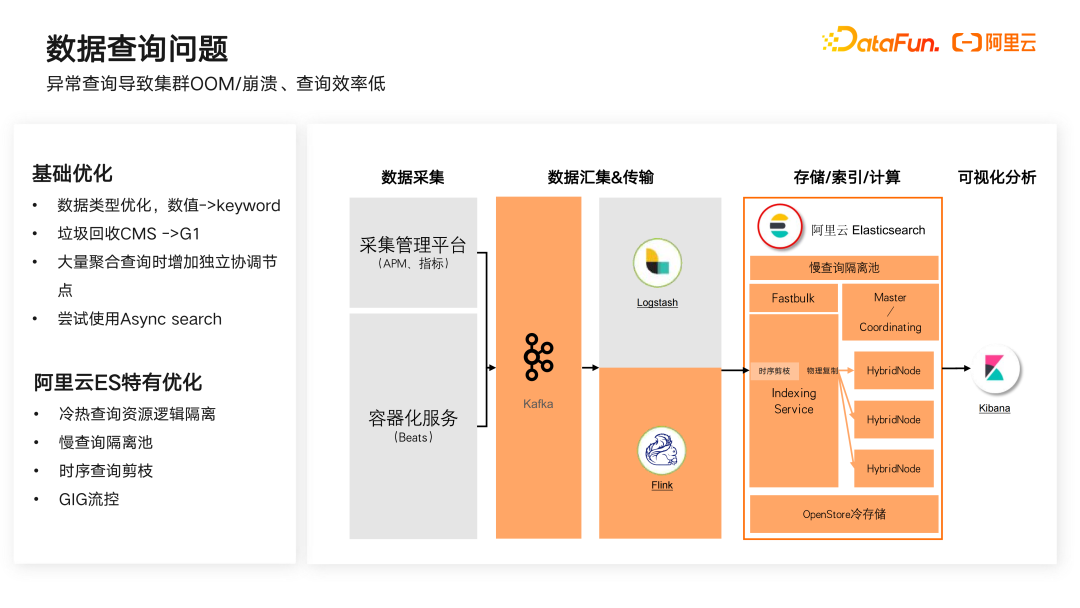
三是数据查询问题。其关键是异常查询导致集群 OOM/崩溃、查询效率低。
我们也采用两方面的解决手段。首先是 Elasticsearch 原生的基础优化
,可以采用数据类型调优的手段,典型的是将数值类型数据替换为 Keyword,能够使整体查询效率得到指数级的提升;将垃圾回收的方式从 CMS 改为 G1,在大内存如 32GB 的情况下是非常好的选择;在大量聚合查询时增加独立协调节点;尝试使用异步搜索 Async Search 等。以上方式都有助于解决查询效率较低的问题。
其次是利用阿里云特有的优化手段
。比如冷热查询资源逻辑隔离,基于冷热共享节点设置冷数据的资源阈值,降低冷数据对热数据的查询效率影响;设置慢查询隔离池,将慢查询请求隔离到内存空间,避免了单个慢查询请求对整个集群造成影响;在时序数据写入方面采用剪枝的方式,将时间字段比较接近的文档放在相近的 Segment 中,从而避免多个节点或分片之间的查询,节省了查询消耗;对于协调节点,还可以采用 GIG 流控的方式,通过监测数据节点的压力获取返回的时效性,来选择最优节点进行流量分发。
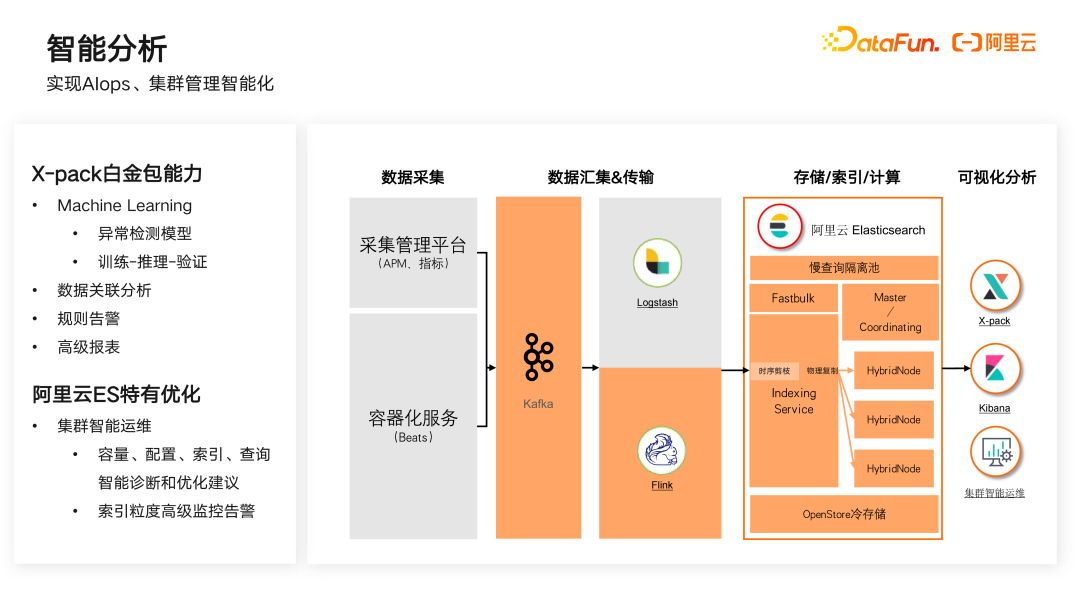
四是智能分析。其关键目标是实现 AIops、集群管理智能化。
一方面 Elasticsearch 云上版本可以提供免费的 X-pack 白金包能力,包含了机器学习、数关联分析、规则警告、高级报表等高级功能。另外阿里云 Elasticsearch 特有优化功能提供了集群智能运维工具,可以从集群管理层面实现整体的智能运维,包含里容量、配置、索引、查询等智能诊断和优化建议,以及索引粒度的高级监控告警,能够通过简单地配置来实现智能运维。
以上就是运维全观测系统整体架构和能力的优化演进方案,接下来我们看具体的案例。
--
03/案例 Usecase
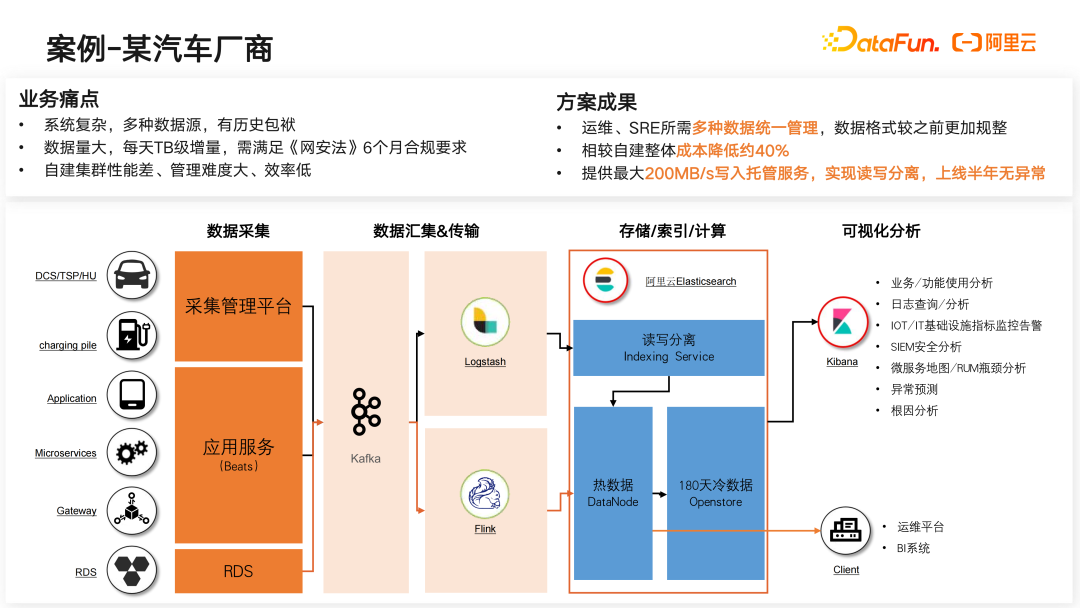
以某汽车厂商为例,该用户希望将其原有的业务系统进行升级。它的业务痛点一是系统越来越复杂且分布式、容器化越来越多,数据采集的来源也越来越多,存在一定的历史包袱,无法进行数据迁移;二是数据存量和增量较大,且需要满足《网安法》6个月合规要求,整体数据量接近于 PB 级;三是自建的集群性能差、管理难度大,频繁出现故障导致被业务方投诉。
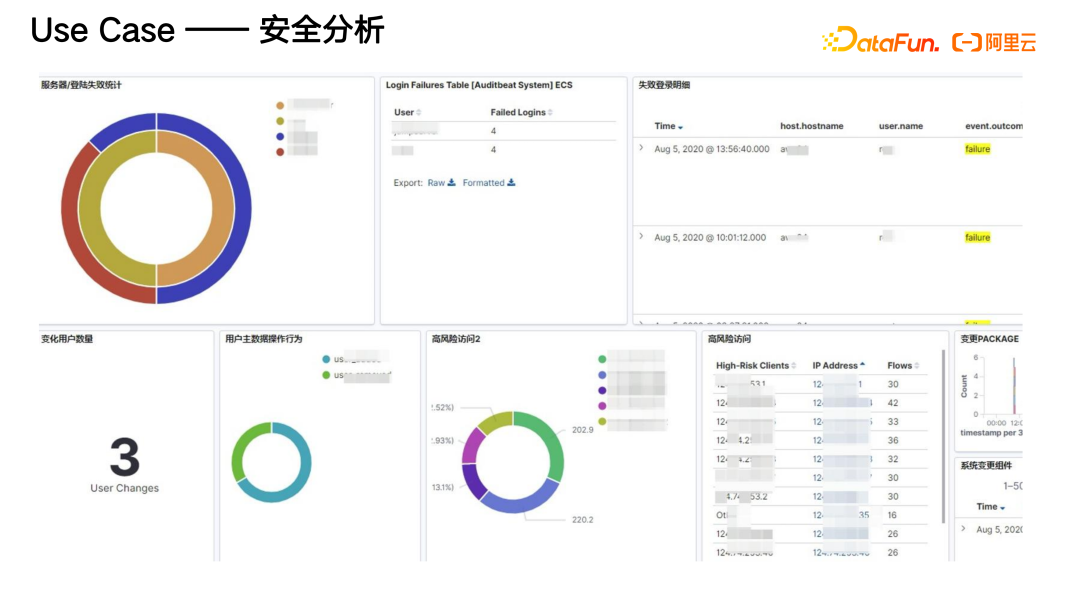
经过我们一系列的优化和重构,按照运维全观测系统的架构和能力演进方案和思路,将写入前链路进行重构,引入更优的预处理插件提高写入效率,将核心引擎从开源 Elasticsearch 替换为阿里云 Elasticsearch,借助阿里云 Elasticsearch 的 IndexingService、Openstore 等能力。在提高集群整体写入性能的同时又降低了成本。最终的方案成功助力该汽车厂商相较其自建集群整体成本降低约 40%;提高了集群整体写入性能,最高峰值达到 200MB/s;整个集群完全实现读写分离,上线半年集群整体无异常。基于这套系统的能力及以上方案成果,该汽车厂商接入了更多的业务线,比如将安全分析、IoT 相关的指标数据等都放到云上进行统一管理,进一步又基于这些结构化和非结构化数据进行异常监测及相关的数据分析。
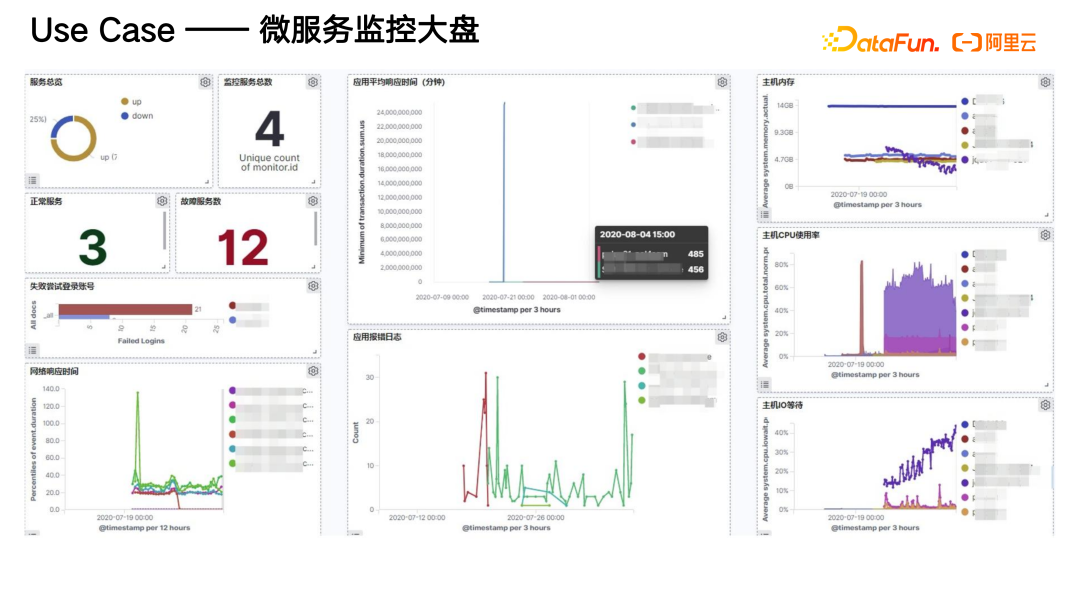
下面是该案例中具体的微服务监控大盘。它实现了对微服务的整体监控,同时也针对安全事件有整体的分析。
最后欢迎大家试用阿里云 Elasticsearch,本文方案中涉及的详细功能点均可参考以下指导文档。
K8S 全观测实战:https://help.aliyun.com/document_detail/210065.html
IndexingService 最佳实践:https://help.aliyun.com/document_detail/217950.html
Openstore 最佳实践:https://help.aliyun.com/document_detail/317694.html
多种迁移方案:https://help.aliyun.com/document_detail/170095.html
SREWorks:https://github.com/alibaba/SREWorks/blob/main/README-CN.md
物理复制能力:https://help.aliyun.com/document_detail/170494.html
Bulk 聚合:https://help.aliyun.com/document_detail/185896.html
Gig 流控:https://help.aliyun.com/document_detail/189754.html
冷热共享隔离:https://help.aliyun.com/document_detail/393496.html
索引压缩:https://help.aliyun.com/document_detail/161329.html
时序索引剪枝:https://help.aliyun.com/document_detail/171099.html
慢查询隔离池:https://help.aliyun.com/document_detail/189717.html
高级监控告警:https://help.aliyun.com/document_detail/171538.html
集群智能运维:https://help.aliyun.com/document_detail/90391.html
今天的分享就到这里,谢谢大家。
<hr/>
分享嘉宾
闫勖勉(三秋)
阿里云计算平台事业部 产品解决方案架构师
阿里云计算平台大数据&AI 解决方案架构师。
<hr/>
DataFun新媒体矩阵
<hr/>
关于DataFun
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。
回复
使用道具
举报
梦先知
梦先知
当前离线
积分
5
0
主题
4
帖子
5
积分
新手上路
新手上路, 积分 5, 距离下一级还需 45 积分
新手上路, 积分 5, 距离下一级还需 45 积分
积分
5
发消息
发表于 2025-3-15 08:55:01
|
显示全部楼层
站位支持
回复
使用道具
举报
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
快速回复
返回顶部
返回列表


 发表于 2022-11-30 13:12:02
发表于 2022-11-30 13:12:02